Data Focused Architecture
Data Focused Architecture (DFA) is a software architecture that prioritises the flow of data through the system. It is best suited for systems whose main purpose is to ingest, process and output data, especially for systems that process data in near real-time. All components in the DFA are defined by their position in the pipelines and their role in the processing of data.
Main Principles
System architecture is always about choosing some features and priorities at the expense of all others. With DFA we optimise for the following:
- Clear intake and output boundaries (isolation from external influences).
- Linear data flow.
- Clearly defined expectations of correctness.
- Clearly defined units of data.
- Traceability.
- Latency from one end of the system to the other.
Architecture Components
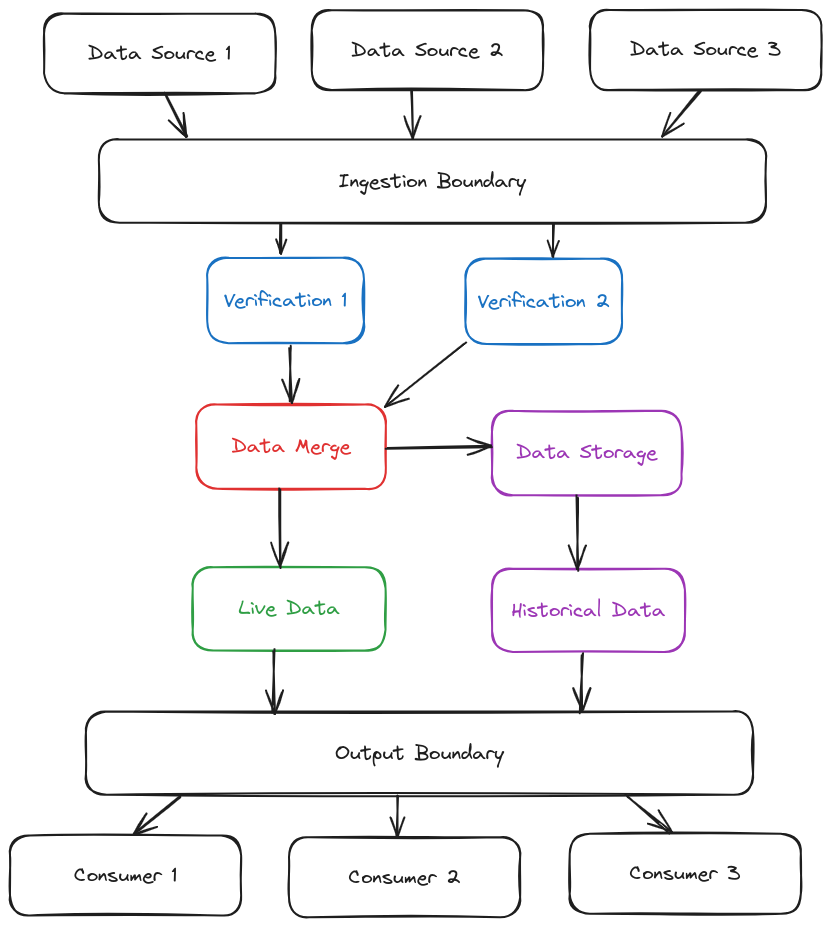
Data Sources
The DFA architecture always starts with data sources feeding into the ingestion boundary. Data source components are usually separate components that stand between the actual external data source and the ingestion boundary. They have a threefold task:
- Transform data into the system-internal standardised representation.
- Add traceability metadata.
- Assure correctness to parsing from the external source.
These sources should be as simple as possible while achieving the three goals mentioned above. When developing them, remember that their task is not to achieve the correctness to the objective truth, but only the correctness of parsing from the source. This means that if an external source sends bad data, data source components should process it and pass it on indiscriminately.
Ingestion Boundary
Ingestion boundary is usually a form of API that can receive data based on its type. While we should protect the ingestion boundary from unauthorised ingestion of data, the API itself should not discriminate by source, but by type. So if two data sources deliver the same type of data, they send it to the same endpoint at the ingestion boundary. The ingestion boundary should also not be dependent on the existence of a particular data source to protect the system from failures and similar problems with third-party data sources.
Verification Components
Verification components consume data at the endpoints of the ingestion boundary. As a rule, there should be one verification component per data type. Verification components have the following tasks:
- De-duplication of data points. Remember to also change the metadata to show multiple sources for the same data point.
- Discard clearly invalid data points, such as outliers, out-of-range values and data points with missing properties.
- Include a reliability score in the metadata for data points that are passed to the merge component.
- Carry out filtering and smoothing if necessary.
Data Merge
Data merge component is the critical centre point of the DFA system and should be designed with redundancy and high availability in mind. It takes data from all verification components and merges them into a single picture of real-time reality. Data merge plays the following tasks:
- Ensures correctness with respect to reality.
- Stores data for post-processing and retrieval.
- Holds state.
Live Data
Optional component for systems where correctness to reality and representational correctness aren't the same. If for example the API offers 3 different levels of subscription with each of them receiving more data, we could design 3 live data components, each of them filtering for correct tier.
Historical (Sideline) Components
Optional component for systems where correctness in respect to reality and representational correctness aren't the same thing. For example, if the API offers 3 different subscription levels, each receiving more data, we could design 3 live data components, each filtering for the correct tier. This assures everyone gets the data they are supposed to get
Output Boundary
Outbound boundary is a standardised API for our system. It is the place where all consumers, such as websites, mobile applications and third-party consumers, receive the data from our system. One of its main goals is to protect the system from consumer issues, such as malicious or erroneous requests, high load and outages.
Consumers
The consumers are the final output of the DFA system. They convert data from the standardised form used throughout the DFA system into a form that end users can use. If required, they can also convert SI units, UTC timestamps and similar standards used in technical systems.
Conclusion
DFA ensures linearity of data flow, traceability of data through the system and clear assumptions of correctness at every step of the way. Thanks to these features, we can avoid duplicate data checks and circular data flows and ensure that we can quickly track down any data-related problem in the system. The system is also isolated from its sources and consumers.
The main costs of this approach arise from the increased data flow due to metadata and standardised data units, the reliability requirements of the components, especially data merge and the relatively large number of moving parts, with most components performing only a small number of limited functions.